

Treating Integration as a Sprint Instead of an Architecture Layer
Assuming FHIR Means Plug-and-Play
Ignoring HL7 v2 Because It Feels Legacy
Building Read-Only When Your Product Needs Write-Back
Underestimating the Security and Compliance Surface
Testing in Sandbox but Not Planning for Production Variance
No Strategy for Multi-EHR from the Start
FAQ
Most of the EHR integration challenges we see in 2026 aren’t new. They’re the same ones that burned startups in 2023 and 2024 – teams just keep discovering them the expensive way. A founder signs a pilot, the engineering team starts building against the FHIR API, and within weeks, the project stalls on problems that had nothing to do with code: security reviews that outlast the build, HL7 v2 feeds nobody mentioned during scoping, and write-back requirements that tripled the timeline.
Here are seven EMR/EHR integration mistakes that healthcare startups and RCM teams consistently underestimate, and what to do about each one before it costs you a quarter of your roadmap.
Treating Integration as a Sprint Instead of an Architecture Layer
This one is the most expensive healthcare integration mistake, and it usually happens before a single line of integration code gets written. Most teams approach their first EHR integration the same way they’d approach any product feature: scope it, sprint it, ship it. The problem is that EHR integration isn’t a feature – it’s infrastructure.
When you hard-wire Epic-specific logic into your application layer during a two-week sprint, you create a pattern that breaks the moment you onboard a second health system (or even a second Epic instance with a different configuration). We see this constantly: a startup “finishes” integration, then spends three to four months untangling it when customer two uses the same vendor but different workflows, code sets, and security requirements.
Why the Architecture Mindset Matters Early
Integration needs its own layer in your stack, separate from your product logic. That means:
- An abstraction that translates between your internal data model and EHR-specific representations
- A mapping and configuration layer that handles site-to-site differences without forking code
- Logging and observability that treat integration events as first-class telemetry, not an afterthought
This doesn’t mean you build an enterprise integration platform before your first paying customer. It means you draw a deliberate boundary between “our product” and “their EHR” from day one, even if the implementation behind that boundary is simple. For startups navigating this for the first time, a structured FHIR integration roadmap from MVP to market prevents the most expensive early mistakes.
Consultant’s Tip: Allocate your first integration timeline to roughly 60% product-facing work and 40% integration-layer design. That 40% feels like overhead on customer one. It saves you months on customers two through five.

Assuming FHIR Means Plug-and-Play
FHIR is a standard. It is not a specification that every EHR implements in the same way.
Teams assume that because Epic, Oracle Health (formerly Cerner), and others expose FHIR R4 endpoints, the integration will be straightforward. In practice, implementations differ in ways that matter: which resources are populated, what OAuth scopes are available, how paging behaves, and whether search parameters work as documented.
Where the Gaps Surface
In our experience at Itirra, the gaps tend to cluster in three areas:
- Resource coverage. A vendor may expose a FHIR endpoint but return incomplete or inconsistently structured data. The Observation resource at one site might populate every code field; at another, half of the fields are absent or use local coding systems.
- Authorization and scopes. SMART on FHIR implementations vary in how granularly they let you request data. Some environments require separate scope registrations per resource type; others bundle them differently.
- Search and filtering. Just because the spec defines a search parameter doesn’t mean every server supports it, or supports it with the same performance characteristics.
Each gap is small individually. Together, they commonly add two to four weeks to a timeline if you weren’t expecting them.
Common Mistake: Building your data model directly against FHIR resource structures without an internal abstraction. When you connect to a second vendor or even a second Epic instance, field-level differences break your assumptions. Add a thin mapping layer between raw FHIR and your internal model early – it saves you from having to rewrite later.
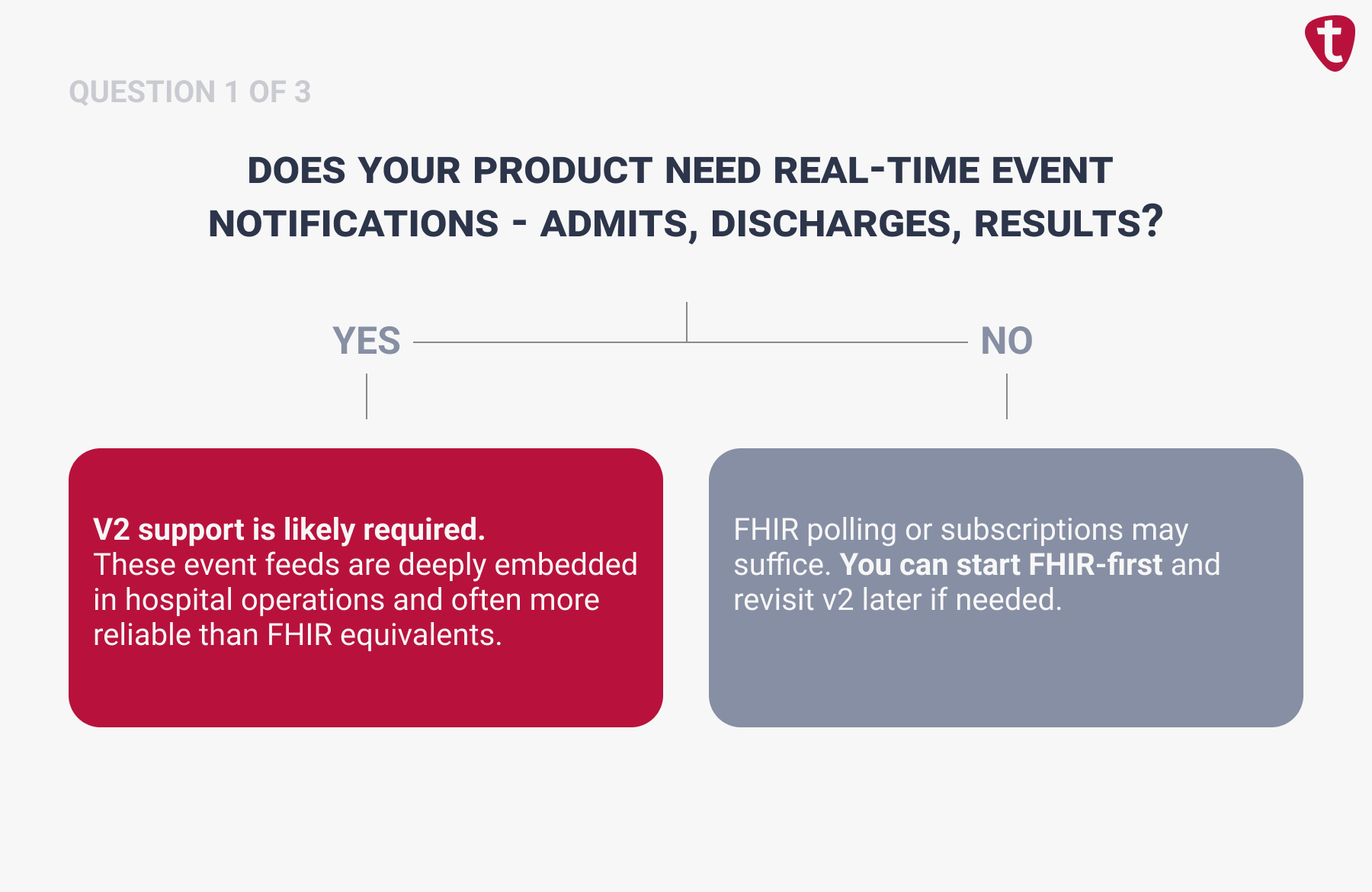
Ignoring HL7 v2 Because It Feels Legacy
It’s tempting to go all-in on FHIR and pretend HL7 v2 doesn’t exist. After all, v2 is decades old, pipe-delimited, and not something anyone puts on a pitch deck.
But here’s the reality: many hospital workflows still run on HL7 v2 messages – ADT (Admit-Discharge-Transfer) feeds, lab results, order notifications. These are deeply embedded in clinical operations, and in many cases, the EHR sends them more reliably and with richer operational context than the FHIR equivalent.
When v2 Still Wins
Similarly, RCM teams relying on charge capture or billing event triggers frequently find that the data they need flows through v2 channels long before it surfaces in a FHIR endpoint. This is one reason RCM execution systems still depend on deep EHR integration rather than API-only approaches.
The right approach isn’t “v2 or FHIR.” It’s knowing which data flows are best served by each protocol at your target sites, and designing your integration layer to accommodate both without coupling your product logic to either.
Consultant’s Tip: Design your internal data model around FHIR concepts, but build a v2 ingest layer that normalizes messages into your model. You don’t need to love v2 – you need to handle it.

Building Read-Only When Your Product Needs Write-Back
Read-only FHIR access is relatively low-friction. You pull patient demographics, conditions, observations – the EHR treats you as a data consumer. Write-back is a fundamentally different game.
When your product writes to the medical record (care plans, clinical notes, diagnostic results), the stakes change. You’re modifying the legal record of care. Health systems respond accordingly: stricter security reviews, clinical governance sign-offs, higher-level OAuth scopes, and significantly more testing.
Read vs. Write-Back: A Decision Framework
Not every product needs write-back at launch. But many teams defer the decision without understanding the cost of retrofitting it later. Use this to calibrate your approach:

If your roadmap includes write-back within 12 months, design for it now, even if you ship read-only first. Retrofitting write capabilities into an architecture built exclusively for reads commonly adds two to three months of rework.
Underestimating the Security and Compliance Surface
Engineering teams tend to treat security reviews as a formality – paperwork you complete after the integration is built. In practice, the compliance and security process at a health system often takes longer than the technical build itself.
A typical Epic or Oracle Health security review involves questionnaires about your hosting environment, encryption, access controls, breach response, and data retention. You’ll sign a BAA and demonstrate HIPAA compliance in handling any PHI. Many health systems also require penetration test results or SOC 2 (System and Organization Controls) reports.
How This Actually Delays Projects
We consistently see teams that build a working integration in six weeks, then spend another eight to twelve weeks navigating security reviews before they can touch production. The technical build was never the bottleneck. The institutional process was.
The fix is simple in concept, but hard in discipline: start the security workstream in parallel with the technical build.
- Request the health system’s security questionnaire and BAA template on day one
- Assign a clear internal owner for compliance documentation
- Budget 40–60 days for the review process, independent of your engineering timeline
Common Mistake: Start security and compliance workstreams in parallel with your technical build, not after. Get your target health system’s security questionnaire and BAA template in the first week of the engagement. If you wait until the integration is code-complete to start compliance, you’ll add two to three months to your go-live.
Testing in Sandbox but Not Planning for Production Variance
Sandbox environments are designed to help you build. They are not designed to simulate what production looks like.
Where sandbox testing falls short
Sandbox data is clean, consistent, and small. Production data is none of those things:
- Patient names contain special characters
- Observation resources are missing expected fields
- Allergy lists hold free-text entries that don’t map to standard codes
- API response times that were instant in sandbox slow to a crawl under real patient volumes
What Changes Between Sandbox and Production
The differences between sandbox and production aren’t subtle — they fall into three categories that no amount of sandbox testing will surface.
Data quality
Production records are messy in ways that test data never is. You’ll encounter missing fields, duplicate entries, legacy coding systems, free-text values where you expected structured codes, and patient names with special characters that break your parser. Every assumption your mapping logic makes against clean sandbox data is an edge case waiting to happen in production.
Volume and performance
Sandbox calls return quickly because the dataset is tiny. Sandbox datasets are small, so every API call returns instantly. In production, queries against large patient populations behave differently – paging logic changes, response times spike, and you’ll need batching or throttling strategies that never came up during development.
Environment configuration
Even within the same EHR vendor, sandbox and production environments can differ in ways that break a working integration: different endpoint URLs, different credential flows, VPN or network allowlisting requirements, and even different FHIR resources enabled. Don’t assume that “works in sandbox” means “works in production with the same vendor.”
Build a dedicated production-hardening phase into your timeline between sandbox sign-off and go-live. This is where you catch the problems that would otherwise surface on day one in front of real clinicians.
Consultant’s Tip: Before go-live, ask your health system partner for de-identified or synthetic data that reflects production complexity, not sandbox cleanliness. That single request surfaces most of the issues that would otherwise hit you with live clinical users watching
No Strategy for Multi-EHR from the Start
You don’t need to support five EHRs on day one. But you do need to design your first integration so that adding a second vendor doesn’t require rewriting it.
This is one of the most expensive EHR interoperability challenges to fix after the fact. Teams that build for one vendor without any abstraction spend months re-platforming when market demand forces multi-vendor support.
A Multi-EHR Sequencing Guide
You don’t need to support every EHR on day one. But you do need a strategy that prevents vendor lock-in from compounding with each new customer. Here’s a realistic sequence:
Months 0–6: First EHR
Follow the revenue – build for whichever vendor your first paying customer uses. Go deep on read and write for your core workflows. If this is your first production EHR integration, this is the phase where bringing in an integration consultant has the highest ROI.
Months 6–12: Abstraction layer
Before starting your second vendor, extract EHR-specific logic into a contained adapter layer. Your product should speak your domain language, not “Epic” or “Oracle Health.” Adapters translate.
Months 12–18: Second EHR vendor
With clean abstraction in place, the second vendor should reuse a significant portion of your first integration’s patterns, commonly in the range of 60–70%.
Months 18+: Long-tail strategy
For smaller EHR vendors, evaluate whether direct integration or a middleware aggregator gives better ROI based on customer deal size and required depth.
At Itirra, we often help teams design this abstraction layer during their first integration, so the second vendor doesn’t require a rewrite. A few extra weeks of upfront design versus months of re-platforming later.
FAQ
Treating integration as a one-off feature instead of a foundational architecture layer. This single decision creates compounding technical debt that slows down every subsequent customer onboarding, every new data flow, and every additional EHR vendor you need to support.
Plan for three to six months from kickoff to live patient data. The technical build is often the shorter piece – security reviews, BAA negotiations, credential provisioning, and health system IT coordination commonly account for half the elapsed calendar time.
A basic read-only FHIR integration might take four to eight weeks of development on its own, but a production deployment with write-back, compliance review, and real-world data validation extends well beyond that. Teams with prior experience or EHR integration consulting support tend toward the shorter end.
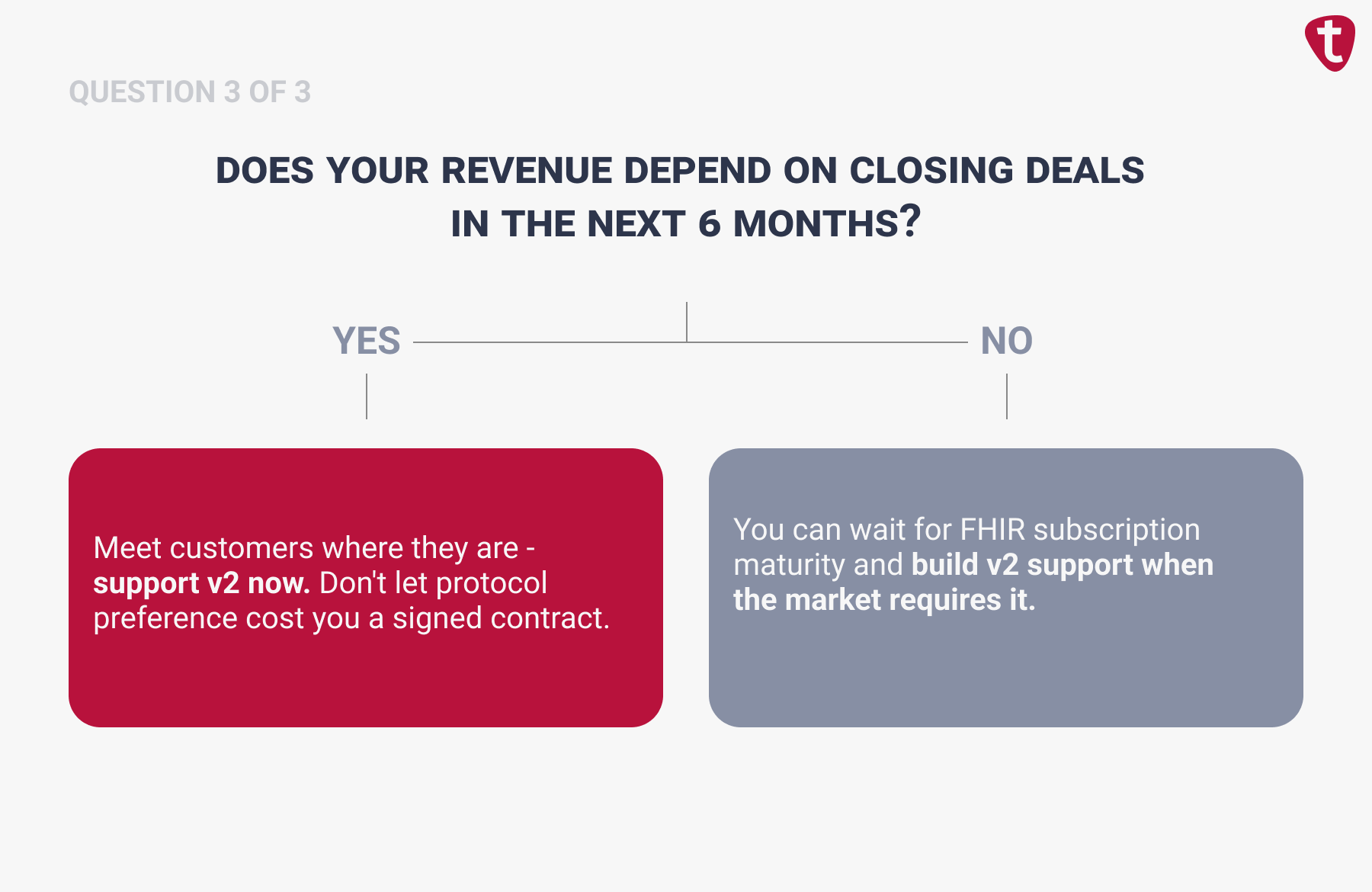
FHIR R4 is the right starting point for most clinical data reads, but it’s rarely sufficient on its own. If your product requires real-time event-driven data (ADT notifications, lab routing, certain billing triggers) many health systems still deliver those over HL7 v2. Most production integrations use a combination of FHIR, v2 messaging, and sometimes vendor-specific APIs to cover the full range of data and workflow requirements. Confirm with your target customers what interfaces they actually support before committing to a single protocol.
It depends on your team’s experience, your timeline, and whether integration is core to your product or supporting infrastructure. If real-time EHR data is central to what you sell, you’ll need deep in-house expertise long-term. But if you’re navigating production EHR environments for the first time under sales pressure, especially with an enterprise deal that needs a live integration in under 90 days, an experienced healthcare integration consultant compresses months of trial and error into weeks and helps you avoid architectural mistakes that are expensive to unwind.
At Itirra, this is the engagement we run most often – if you’re weighing that decision, schedule a consultation, and we’ll figure out which path fits your situation.
The core technical challenges are similar, but RCM teams often deal with higher data volumes, more complex data transformation requirements, particularly mapping clinical data to billing codes, and stricter accuracy demands since errors directly affect revenue. They also tend to need integration with a wider range of systems beyond the EHR, including clearinghouses and payer platforms.
Start with an abstraction layer: a common internal data model that decouples your application logic from any single EHR’s API. Build vendor-specific adapters that handle translation, authentication, and data mapping for each target system. This lets you add new EHR vendors incrementally without rewriting your core application. Ideally, design this abstraction during your first integration so the second vendor doesn’t require a re-platform.
Ongoing maintenance. Teams budget for the initial build but not what follows: API version changes, new site onboarding, production monitoring, and edge cases that only surface with real clinical data. Plan for at least one engineer spending meaningful time on integration operations as you scale past your first deployment.